
Qdrant
Founded Year
2021Stage
Series A | AliveTotal Raised
$37.79MLast Raised
$28M | 2 yrs agoMosaic Score The Mosaic Score is an algorithm that measures the overall financial health and market potential of private companies.
+69 points in the past 30 days
About Qdrant
Qdrant focuses on providing vector similarity search technology, operating in the artificial intelligence and database sectors. The company offers a vector database and vector search engine, which deploys as an API service to provide a search for the nearest high-dimensional vectors. Its technology allows embeddings or neural network encoders to be turned into applications for matching, searching, recommending, and more. Qdrant primarily serves the artificial intelligence applications industry. It was founded in 2021 and is based in Berlin, Germany.
Loading...
Qdrant's Product Videos

ESPs containing Qdrant
The ESP matrix leverages data and analyst insight to identify and rank leading companies in a given technology landscape.
The vector databases market focuses on providing databases optimized for high-dimensional, vector-based data. These databases are designed to efficiently store, manage, and query large volumes of vectors — i.e., mathematical representations of data points in multidimensional space. Vector databases cater to a wide range of applications, including machine learning, natural language processing, rec…
Qdrant named as Outperformer among 10 other companies, including Oracle, Elastic, and Pinecone.
Qdrant's Products & Differentiators
Qdrant Open Source
Qdrant Open Source: Allows users to deploy Qdrant locally with Docker under the Apache 2.0 license. We’ve seen over 250 million downloads across all our open-source packages.
Loading...
Research containing Qdrant
Get data-driven expert analysis from the CB Insights Intelligence Unit.
CB Insights Intelligence Analysts have mentioned Qdrant in 7 CB Insights research briefs, most recently on Oct 20, 2025.

Oct 20, 2025 report
Book of Scouting Reports: 2025’s Digital Health 50
Sep 5, 2025 report
Book of Scouting Reports: The AI Agent Tech Stack
May 16, 2025 report
Book of Scouting Reports: 2025’s AI 100
Apr 24, 2025 report
AI 100: The most promising artificial intelligence startups of 2025
Oct 13, 2023
The open-source AI development market map
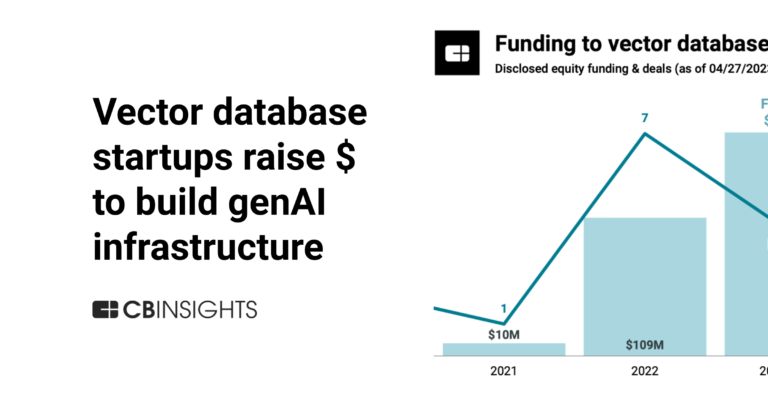
Expert Collections containing Qdrant
Expert Collections are analyst-curated lists that highlight the companies you need to know in the most important technology spaces.
Qdrant is included in 4 Expert Collections, including Artificial Intelligence (AI).
Artificial Intelligence (AI)
16,409 items
Companies developing artificial intelligence solutions, including cross-industry applications, industry-specific products, and AI infrastructure solutions.
Generative AI
2,950 items
Companies working on generative AI applications and infrastructure.
AI 100 (2025)
100 items
AI 100 (All Winners 2018-2025)
100 items
Latest Qdrant News
Oct 29, 2025
Introduction In e-commerce, success hinges on one thing: showing the right product to the right user at the right time. Whether it’s search results, recommendations, or personalized feeds, every interaction shapes how a customer feels about a brand. And behind that experience lie three pillars: relevance, personalization, and multilingual understanding. Relevance: When a shopper searches for “waterproof hiking backpack,” the system shouldn’t serve random fashion bags or travel rucksacks. It should surface backpacks designed for trekking and hiking, tuned to the user’s intent, not just their keywords. Personalization: Now imagine two users typing “smartwatch.” User A has been exploring fitness trackers, so they should see smartwatches with heart-rate monitoring, GPS, and long battery life. User B, however, has been browsing luxury accessories, so the system should recommend high-end models from Apple or TAG Heuer. This level of intelligence comes from learning patterns hidden in browsing history, cart behavior, and demographic context. Multilingual Understanding: A global shopper base means diverse languages. If a user in India searches for “चाय का कप” (tea cup), they should instantly see the same results as someone searching “tea mug” in English. To deliver this kind of smart retrieval, we need to move beyond simple keyword matching. Queries and product descriptions must be represented as vectors — mathematical representations that capture meaning and relationships between words while preserving important keyword signals. That’s where Qdrant comes in. Acting as the engine for intelligent search and recommendation, Qdrant stores, indexes, and searches these vector representations efficiently at scale. With built-in support for sparse, dense, and hybrid retrieval, it enables developers to build real-time product recommendations, personalized search, and multilingual discovery systems that truly understand what users mean — not just what they type. 2. Lexical Retrieval vs Dense Retrieval vs Sparse Retrieval 2.1 Lexical Retrieval Lexical retrieval converts text into bag-of-words vectors, where each word is treated as a separate dimension and assigned a statistical weight using models such as TF-IDF or BM25. Only the words that appear in the document have non-zero weights. Only words that appear in the document have non-zero weights; words absent from the document receive a weight of zero. In this approach: Common words across documents get low weight because they appear frequently and carry less distinguishing power. Rare words get high weight, since they occur less often and are assumed to be more informative. Example: Product A:“40L trekking backpack with rain cover” Product B:“Alpine brand leather handbag” Product C:“Travel rucksack for camping trips” Product B might score high because “alpine” is a rare word, even though it has nothing to do with hiking. Product C might also rank high because of the keyword “rucksack”, despite being related to general travelling and not hiking. Understanding that “trekking backpack” (Product A) is semantically the closest match to “hiking backpack” is missing here. 2.2 Dense Retrieval Dense Retrieval represents text, such as user queries and product descriptions, as dense vectors (embeddings) in a low-dimensional space. Instead of relying on exact word matching, neural models like BERT, GPT capture the semantic meaning of text, so that texts with similar meanings have similar vector representations, even when they use completely different words. Example: Product A:“40L trekking backpack with rain cover” Product B:“Alpine brand leather handbag” Product C: “Travel rucksack for camping trips” Model will give high score to Product A which is correct as it’s a backpack meant for trekking and includes a rain cover. Product B is clearly irrelevant, and the model will give it a low similarity score. Product C, however, will get a high score even though it’s a travel rucksack, not a waterproof hiking backpack. This happens because the dense model interprets “hiking backpack” and “travel rucksack” as semantically close as both represent bags for carrying items outdoors. As a result it fails to capture the specific intent that the user wants a waterproof technical hiking bag, not a travel bag for clothes. Also, we need to remember that dense models are computationally expensive. 2.3 Sparse Retrieval Sparse retrieval represents the new generation of search models that combine the precision of lexical retrieval ( TF-IDF , BM25) with the semantic depth of dense retrieval (BERT, GPT). Instead of assigning fixed statistical weights to words, sparse neural models such as SPLADE and miniCOIL use transformer-based architectures to learn which terms are truly important and how they relate contextually to others. Because they leverage sparse representations and rely on lightweight indexing structures (like inverted lists) rather than computationally expensive vector similarity searches, sparse retrieval is more efficient and scalable than dense models — especially during query time. Example: Product A:“40L trekking backpack with rain cover” Product B:“Alpine brand leather handbag” Product C: “Travel rucksack for camping trips” Product C, which was wrongly boosted by dense retrieval in the above example, will now get a lower score since it lacks matching terms, though “hiking backpack” and “travel rucksack” are semantically close. Product A will get the highest score. Product B will get the lowest score 3. SPLADE vs miniCOIL Both SPLADE and miniCOIL are sparse neural models, that is, they represent text as high-dimensional, sparse vectors where most word dimensions are zero, but the important words have learned weights capturing semantic meaning. 3.1 SPLADE SPLADE stands for Sparse Lexical and Expansion Model for Information Retrieval. It is a sparse neural model in which queries and documents are represented as vectors with mostly zero values, just like TF-IDF or BM25, but the non-zero weights are learned using transformer-based models like BERT. SPLADE also supports term expansion, meaning the model can assign weights to tokens that do not explicitly appear in the document but are contextually related to those that do. This powerful feature allows the model to better capture the semantic context of the document and improve retrieval performance. For example: SPLADE output: { Assigns learned weights that show how important each word is. Adds additional semantic terms not present in input/document such as bluetooth, music, sound ,earphones and audio. 3.2 miniCOIL miniCOIL, unlike SPLADE, does not expand documents with new terms; it only reweights the existing words based on their contextual importance. As a result, the index size remains smaller and more compact than that of SPLADE, enabling faster and more efficient retrieval with higher precision. However, since miniCOIL focuses solely on exact terms and lacks semantic expansion, its recall is lower compared to SPLADE, which can retrieve a broader range of semantically related results. 4. Qdrant Architecture } The JSON object above represents a point in Qdrant. The vector is a numerical representation of the product’s title or description. Each point corresponds to one product in the search system. When many such points are stored together, they form a collection named products_collection. A payload is the additional JSON metadata attached to a vector, used for filtering, ranking, or applying business logic during search. 5. Product Search Using Qdrant Let us now explore a comparative study of lexical search, dense retrieval, and sparse neural retrieval using Qdrant for an e-commerce use case. Install the following Python libraries: ! pip install qdrant-client products = [ {"id": "S001", "title": "Nike Air Zoom Pegasus", "description": "Lightweight breathable running shoes", "brand": "Nike", "category": "Running", "price": 8999}, {"id": "S002", "title": "Adidas Ultraboost 5.0", "description": "Cushioned marathon runner with energy return", "brand": "Adidas", "category": "Running", "price": 12999}, {"id": "S003", "title": "ASICS Gel-Kayano Stability", "description": "Comfortable long distance support running shoes", "brand": "ASICS", "category": "Running", "price": 11999}, {"id": "S004", "title": "Puma Velocity Nitro 2", "description": "Nitro foam responsive daily trainer", "brand": "Puma", "category": "Running", "price": 8499}, {"id": "S005", "title": "Skechers GoWalk", "description": "Soft cushioned walking shoes", "brand": "Skechers", "category": "Walking", "price": 4999}, {"id": "S006", "title": "Clarks Oxford Leather", "description": "Classic formal leather shoes", "brand": "Clarks", "category": "Formal", "price": 7499}, {"id": "S007", "title": "Woodland Trek Waterproof", "description": "Rugged waterproof trekking boots", "brand": "Woodland", "category": "Outdoor", "price": 6999}, {"id": "S008", "title": "Converse Chuck Taylor", "description": "Iconic casual canvas sneakers", "brand": "Converse", "category": "Casual", "price": 3999}, {"id": "S009", "title": "Nike Metcon Trainer", "description": "Stable cross-training gym shoes", "brand": "Nike", "category": "Training", "price": 7999}, {"id": "S010", "title": "Adidas Terrex Trail GTX", "description": "Waterproof trail running shoes with grip", "brand": "Adidas", "category": "Trail", "price": 13999} ] 5.1 Lexical Search(TF-IDF) 5.4 Ranked Results Comparison Lexical retrieval matches exact keywords such as “waterproof” and “running” but lacks semantic understanding. As a result, it may rank Woodland Trek Waterproof above Adidas Terrex Trail GTX simply because of keyword overlap. Dense vector retrieval captures semantic meaning but may overlook exact keyword matches. Sparse neural vector representations (such as SPLADE) combine both strengths — they understand exact terms (e.g., “waterproof”) as well as semantically related ones (e.g., “GTX”, “trail”). Additionally, they offer faster retrieval than dense semantic models, making them both efficient and highly relevant for search applications. 6. Hybrid Retrieval for Multilingual Search -Why Hybrid Approach? Sparse neural models excel at keyword matching while maintaining contextual relevance, but they do not capture cross-language semantics or translation. Dense multilingual embeddings, on the other hand, capture meaning and context across different languages but often lack precision in keyword matching. A hybrid retrieval approach combines the best of both worlds — leveraging the contextual and lexical precision of sparse neural models with the semantic and multilingual understanding of dense embeddings. This results in search outcomes that are both precise and meaningfully aligned across languages. Let’s understand this through a practical e-commerce use case: Multilingual E-commerce Product Dataset : fused = sorted(combined.items(), key=lambda x: x[1], reverse=True) return fused print("\nHYBRID RESULTS (Normalized Score Fusion):") for pid, score in fusion: doc = client.retrieve("products_collection_multilingual", ids=[pid])[0] print(f"→ {doc.payload['title']} | ₹{doc.payload['price']} | combined_score={score:.4f}") Output: The user query is processed through a sparse neural model for keyword precision and semantic understanding, and a dense multilingual model for semantic and cross-language comprehension. Since both models produce scores on different scales, the scores are normalized to a common range [0,1] to ensure fair contribution from both systems during result fusion. Weighted score blending then combines the lexical precision of the sparse model with the semantic depth of the dense model, producing a unified and balanced ranking. The final hybrid results outperform individual models, demonstrating cross-lingual accuracy, context-aware retrieval, and high precision for multilingual product search in e-commerce. 7. Conclusion In modern e-commerce, users expect search results that think like they do — relevant, personalized, and multilingual. Traditional keyword-based search (lexical retrieval) hits exact matches but misses intent. Dense vector search captures meaning but can overlook crucial keywords and domain nuances. Sparse neural retrieval brings the best of both worlds — combining keyword precision with semantic intelligence to deliver results that feel natural and context-aware. This is where Qdrant steps in as the engine behind next-generation product discovery. It unifies sparse, dense, and hybrid retrieval in a single, developer-friendly framework: no complex setup, no trade-offs. By fusing sparse inverted indexing with optimized ANN search, Qdrant makes hybrid queries blazing fast, often returning results in milliseconds even across millions of products. For developers, this means you can build intelligent, low-latency, multilingual search systems that scale effortlessly — whether you’re recommending sneakers, gadgets, or luxury travel gear. Qdrant lets you move beyond search that just matches words to search that truly understands meaning. 8. References
Qdrant Frequently Asked Questions (FAQ)
When was Qdrant founded?
Qdrant was founded in 2021.
Where is Qdrant's headquarters?
Qdrant's headquarters is located at Chausseestrasse 86, Berlin.
What is Qdrant's latest funding round?
Qdrant's latest funding round is Series A.
How much did Qdrant raise?
Qdrant raised a total of $37.79M.
Who are the investors of Qdrant?
Investors of Qdrant include 42CAP, Unusual Ventures, Spark Capital, IBB Ventures, Amr Awadallah and 7 more.
Who are Qdrant's competitors?
Competitors of Qdrant include Langbase and 8 more.
What products does Qdrant offer?
Qdrant's products include Qdrant Open Source and 3 more.
Loading...
Compare Qdrant to Competitors

Pinecone specializes in vector databases for artificial intelligence applications within the technology sector. The company offers a serverless vector database that enables low-latency search and management of vector embeddings for a variety of AI-driven applications. Pinecone's solutions cater to businesses that require scalable and efficient data retrieval capabilities for applications such as recommendation systems, anomaly detection, and semantic search. Pinecone was formerly known as HyperCube. It was founded in 2019 and is based in New York, New York.

ApertureData operates within the data management infrastructure domains. The company's offerings include a database for multimodal AI that integrates vector search and knowledge graph capabilities for AI application development and data management. ApertureData serves sectors that require AI applications, including generative AI, recommendation systems, and visual data analytics. It was founded in 2018 and is based in Los Gatos, California.

Weaviate is a company that develops artificial intelligence (AI)-native databases within the technology sector. The company provides a cloud-native, open-source vector database to support AI applications. Weaviate's offerings include vector similarity search, hybrid search, and tools for retrieval-augmented generation and feedback loops. Weaviate was formerly known as SeMi Technologies. It was founded in 2019 and is based in Amsterdam, Netherlands.
Hyperspace is a technology company that operates in the cloud-native database and search technology sectors. The company offers an elastic compatible search database that integrates vector and lexical search capabilities. Hyperspace serves sectors that require search solutions, such as e-commerce, fraud detection, and recommendation systems. It was founded in 2021 and is based in Tel Aviv, Israel.
LanceDB operates as a serverless vector database for artificial intelligence (AI) applications. The company builds applications for generative artificial intelligence (AI), recsys, search engines, content moderation, and more. It was founded in 2022 and is based in San Francisco, California.
Vespa specializes in data processing and search solutions within the AI and big data sectors. The company offers an open-source search engine and vector database that enables querying, organizing, and inferring over large-scale structured, text, and vector data with low latency. Vespa primarily serves sectors that require scalable search solutions, personalized recommendation systems, and semi-structured data navigation, such as e-commerce and online services. It was founded in 2023 and is based in Trondheim, Norway.
Loading...