
LlamaIndex
Founded Year
2023Stage
Incubator/Accelerator | AliveTotal Raised
$27.5MMosaic Score The Mosaic Score is an algorithm that measures the overall financial health and market potential of private companies.
+74 points in the past 30 days
About LlamaIndex
LlamaIndex focuses on document automation and artificial intelligence (AI) agent development within the technology sector. The company provides products for parsing, extracting, indexing, and retrieving unstructured data, as well as a framework for building and orchestrating AI workflows. LlamaIndex serves sectors such as finance, insurance, manufacturing, and healthcare, offering solutions for document processing and workflow automation. LlamaIndex was formerly known as GPT Index. It was founded in 2023 and is based in San Francisco, California.
Loading...
ESPs containing LlamaIndex
The ESP matrix leverages data and analyst insight to identify and rank leading companies in a given technology landscape.
The large language model (LLM) application development market provides frameworks, tools, and platforms for building, customizing, and deploying applications powered by pre-trained language models. Companies in this market offer solutions for fine-tuning models on domain-specific data, creating prompt engineering workflows, developing retrieval-augmented generation systems, and orchestrating LLM-p…
LlamaIndex named as Leader among 15 other companies, including Databricks, Cohere, and Weights & Biases.
LlamaIndex's Products & Differentiators
LlamaCloud
LlamaCloud is the knowledge management layer for AI agents. It enables a developer to connect, parse, and index large volumes of complex unstructured document data (PDFs, Powerpoints, and 50+ other document types) so that it’s usable for any downstream agentic workflow. It contains the following features: - Data Connectors to file-based data sources like Sharepoint, S3, Google Drive. - Parsing (LlamaParse): The best GenAI-native document parsing solution that adapts SOTA LLMs/VLMs with heuristic parsing. Can handle tables/charts/complex fonts. - Extraction: Transform unstructured data into highly accurate structured data. - Indexing/Retrieval: Make a large volume of documents searchable for RAG/agents with accurate multimodal indexing/retrieval capabilities.
Loading...
Research containing LlamaIndex
Get data-driven expert analysis from the CB Insights Intelligence Unit.
CB Insights Intelligence Analysts have mentioned LlamaIndex in 7 CB Insights research briefs, most recently on Oct 23, 2025.

Sep 5, 2025 report
Book of Scouting Reports: The AI Agent Tech Stack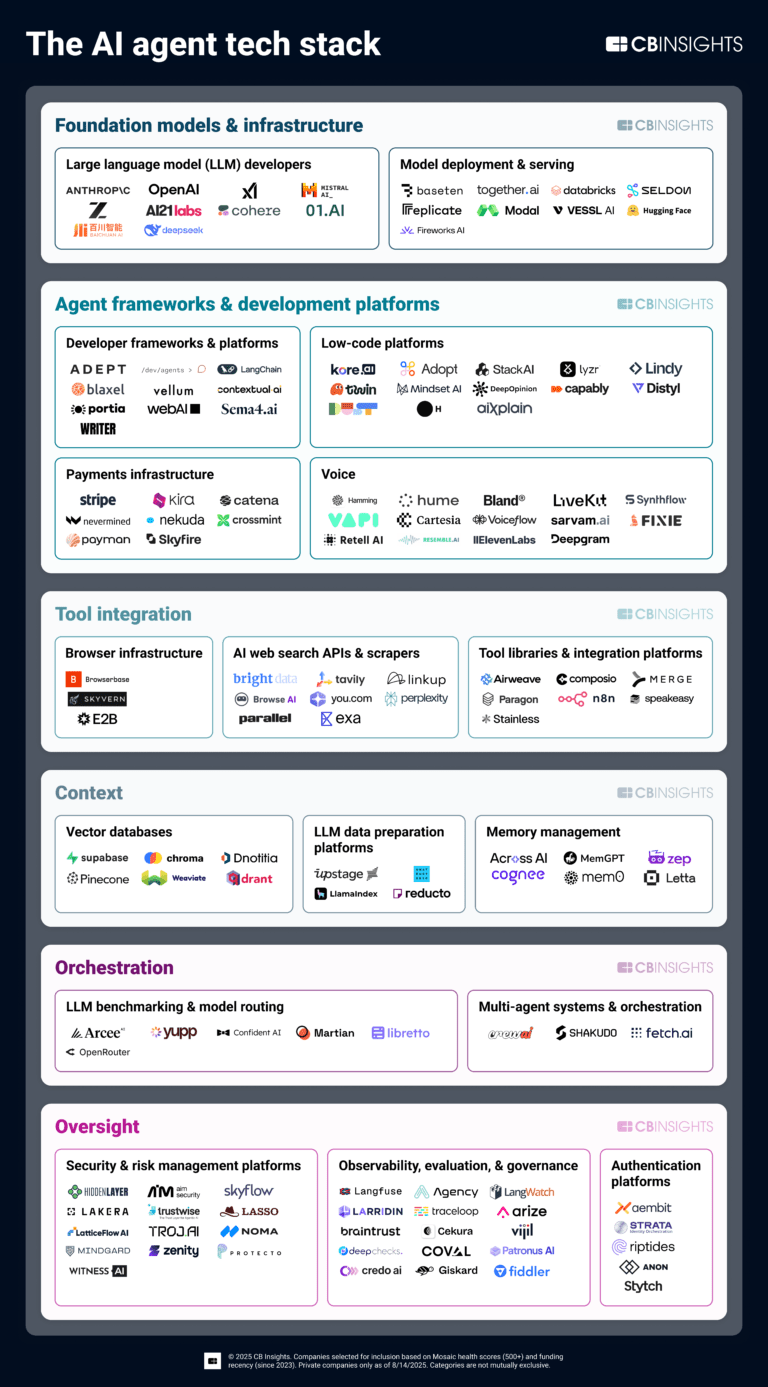
Aug 22, 2025
The AI agent tech stack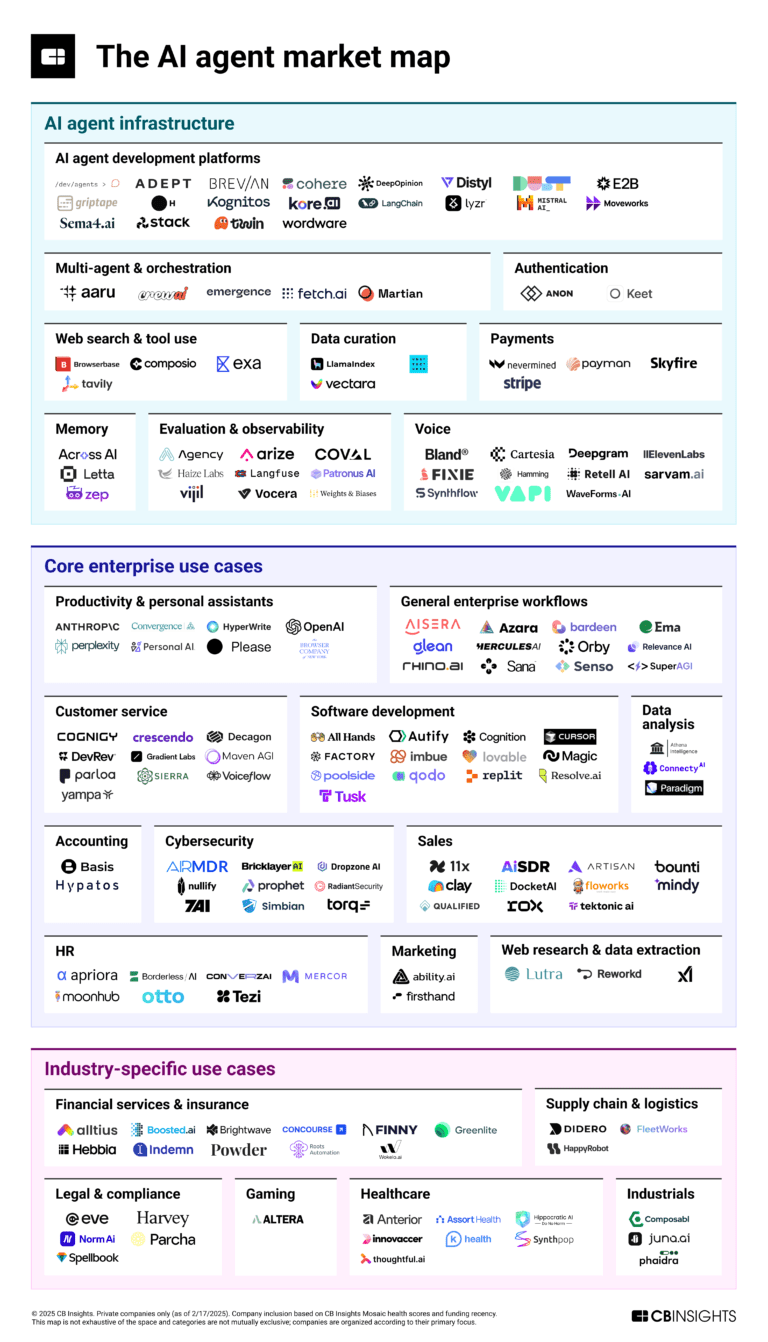
Mar 6, 2025
The AI agent market map
Feb 28, 2025
What’s next for AI agents? 4 trends to watch in 2025
Oct 13, 2023
The open-source AI development market map
Expert Collections containing LlamaIndex
Expert Collections are analyst-curated lists that highlight the companies you need to know in the most important technology spaces.
LlamaIndex is included in 6 Expert Collections, including Artificial Intelligence (AI).
Artificial Intelligence (AI)
37,207 items
Companies developing artificial intelligence solutions, including cross-industry applications, industry-specific products, and AI infrastructure solutions.
Generative AI
2,951 items
Companies working on generative AI applications and infrastructure.
AI Agents & Copilots Market Map (August 2024)
322 items
Corresponds to the Enterprise AI Agents & Copilots Market Map: https://app.cbinsights.com/research/enterprise-ai-agents-copilots-market-map/
AI agents
376 items
Companies developing AI agent applications and agent-specific infrastructure. Includes pure-play emerging agent startups as well as companies building agent offerings with varying levels of autonomy. Not exhaustive.
ITC Vegas 2025
496 items
Based on sponsor list as of 9.22.2025
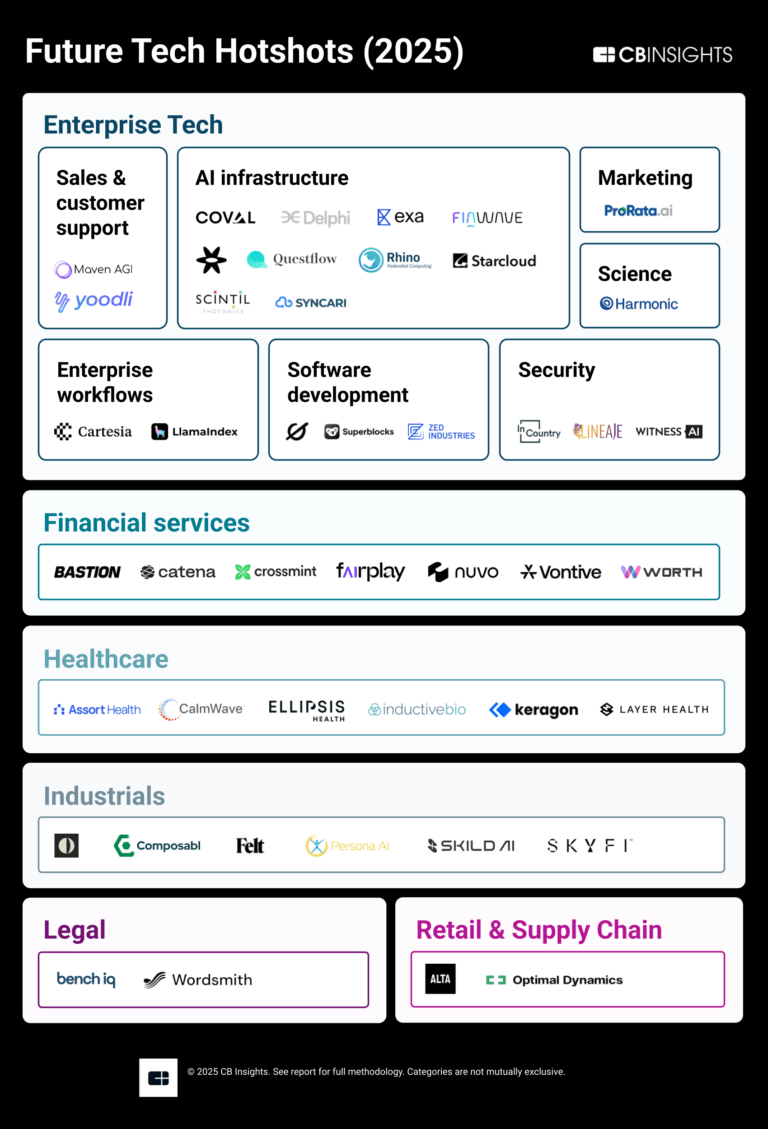
Future Tech Hotshots 2025
45 items
Latest LlamaIndex News
Oct 20, 2025
长上下文窗口、Agent崛起,RAG已死? 向量数据库 Chroma 创始人兼 CEO Jeff Huber 在播客与访谈中抛出「RAG 已死,上下文工程当立」的表述,主张以上下文工程框架取代对「RAG」这一术语的狭义依赖。 对于众多 AI 应用开发者而言,RAG 并不陌生。自 2022 年以来,为解决 LLM 输入长度有限(如 GPT-3.5 的 4K tokens)的问题,RAG 作为一种「外挂」知识库的解决方案,迅速成为行业标准。 其核心逻辑如同搜索引擎:将庞大文档切分成小块,通过向量嵌入和相似度搜索,找到与用户问题最相关的片段,再喂给 LLM 生成答案。 作为近几年最炙手可热的 LLM 应用范式之一,RAG 似乎正在经历一场生存危机。长上下文窗口的崛起和 Agent 能力的进化,正在动摇着它的核心地位。 那么,RAG 真的过时了吗?我们从三篇代表性文章中,梳理了业界对 RAG「生死问题」的不同回答。 RAG 未死,它在进化为「智能体检索」 博客地址:https://www.llamaindex.ai/blog/rag-is-dead-long-live-agentic-retrieval 来自 RAG 基础设施巨头 LlamaIndex 的这篇文章提供了一种演进主义的视角。它不认为 RAG 正在被替代,而是正在经历一个演进阶段,其中 AI 智能体成为一种全新的、更强大的 RAG 架构的核心。 文章指出,RAG 技术已经超越了早期「朴素的区块检索」阶段,进入了一个以「Agentic 策略」为核心的新时代。现代 AI 工程师需要掌握一系列复杂的数据检索技术,如混合搜索、CRAG、Self-RAG 等。 作者以 LlamaCloud 的检索服务为例,系统性地展示了如何从基础的 RAG 逐步构建一个能够智能查询多个知识库的、完全由 agent 驱动的高级检索系统。 第一阶段:基础的「Top-k」检索 作者还提及,在 LlamaCloud 的实现中,除了默认的按区块检索(chunk 模式),还提供了两种额外的文件级检索模式: files_via_metadata:当查询明确提及文件名或路径时(例如,「2024_MSFT_10K.pdf 这份文件说了什么?」),此模式直接检索整个文件。 files_via_content:当查询是关于某个主题的宽泛问题,但需要完整文件作为背景时(例如,「微软的财务前景如何?」),此模式会根据内容相关性检索整个文件。 第二阶段:引入轻量级 agent——自动路由模式 该模式本质上是一个轻量级的 agent 系统。它会首先分析用户的查询,然后智能地判断应该采用上述三种模式(chunk、files_via_metadata 或 files_via_content)中的哪一种来执行检索。这实现了在单一知识库内的检索策略自动化。 第三阶段:扩展至多个知识库——复合检索 API 为了能够同时查询这些分散的知识库,作者介绍了「复合检索 API」。其核心功能是: 整合多个索引:允许将多个独立的索引(例如,「财报索引」和「幻灯片索引」)添加到一个复合检索器中。 智能路由:通过为每个子索引提供描述(例如,「用于公司财务报告」),复合检索器利用一个 agent 层来分析用户查询,并将其路由到一个或多个最相关的子索引。 结果重排:从所有被查询的索引中收集结果,并进行重排序,最终返回最相关的 top-n 个结果。 第四阶段:构建完全由 agent 驱动的知识系统 顶层 agent(复合检索器):接收到用户查询后,该 agent 首先进行 LLM 分类,判断查询与哪个或哪些知识库(子索引)最相关,并将查询分发下去。 例如,当查询「2024 年第四季度财报中的收入增长情况如何?」时,顶层 agent 会识别出「财报」关键词,并将查询路由至 financial_index。 子索引层 agent(自动路由模式):当一个特定的子索引接收到查询后,其内部的 auto_routed 模式 agent 会启动,分析查询的具体意图,并决定在该索引内部使用最合适的检索方法(是按区块、按文件名还是按内容检索)。 例如,对于上述查询,子索引 agent 可能会判断这是一个针对特定信息的问题,从而选择 chunk 模式进行精确区块检索。 通过这种分层 agent 的方法,系统能够以高度动态和智能化的方式响应复杂多样的用户查询,在正确的时间、从正确的知识库、用正确的方式获取最精准的上下文。 作者总结道,简单的 RAG 已经过时,智能体驱动的检索才是未来。高级检索服务通过这种分层、智能的能力,充当着高级 AI 智能体不可或缺的「知识骨干」。 别说 RAG 已死,它正成为一门严肃的工程学科 博客地址:https://hamel.dev/notes/llm/rag/not_dead.html 文章包含 6 个部分,作者邀请多位专家共同系统性地探讨了为什么 RAG 不仅没有死,反而正以前所未有的重要性,进化为构建可靠、高效 AI 应用的核心工程学科。 Part 1 & 2: 重新定义 RAG 与评估范式 Ben Clavié(RAGatouille 作者)和 Nandan Thakur(BEIR、FreshStack 基准测试设计者)首先澄清了核心误解。 Clavié 指出,将所有信息塞入长上下文窗口在经济和效率上都是不切实际的。RAG 的本质(为语言模型提供其训练时未见的外部知识)是永恒的需求。 我们告别的只是幼稚的单向量语义搜索,正如我们用 CSS 升级 HTML,我们正在用更先进的检索技术升级 RAG。 Thakur 则颠覆了传统的评估体系。他认为,像 BEIR 这类为传统搜索引擎设计的基准,其目标是「找到排名第一的正确答案」,这与 RAG 的目标不符。 RAG 系统的检索目标应该是: Part 3 & 4: 新一代检索模型:会推理、无损压缩 Orion Weller(约翰霍普金斯大学)和 Antoine Chaffin(LightOn)介绍了两种突破性的检索模型范式,它们让检索器本身具备了「思考」能力。 Weller 的研究将大模型的指令遵循和推理能力直接嵌入检索过程。他展示了两个模型: Rank1:一个能生成明确推理链的 reranker 模型,它通过「思考过程」来判断相关性,不仅提升了准确率,还发现了许多被以往基准测试忽略的有效文档。 Chaffin 则直指单向量检索的核心缺陷——信息压缩损失。他介绍了「延迟交互」模型(如 ColBERT),这种模型不将整个文档压缩成一个向量,而是保留了每个 token 的向量表示。 这使得一个仅有 150M 参数的小模型,在推理密集型任务上的表现甚至超过了 7B 参数的大模型。同时,PyLate 等开源库的出现,正让这种强大的技术变得前所未有地易于使用。 Part 5 & 6: 架构的进化:从单一地图到智能路由与上下文工程 最后两部分由 Bryan Bischof 和 Ayush Chaurasia,以及 Chroma 公司的 Kelly Hong,将视角从模型本身拉升到系统架构和工程实践。 Bischof 和 Chaurasia 提出,我们不应再寻找那个「完美」的嵌入模型或表示方法。正确的做法是,为同一份数据创建多种表示,就像为同一个地方准备多张不同功能的地图(如地形图、交通图)。 然后,利用一个智能「路由器」(通常是一个 LLM Agent)来理解用户意图,并将其导向最合适的「地图」进行查询。他们的「语义点彩艺术」应用生动地展示了这种架构的灵活性和强大效果。 Kelly Hong 的研究则为「长上下文万能论」敲响了警钟。她提出了「上下文腐烂」现象:随着输入上下文的增长,尤其是在存在模糊信息和「干扰项」时,大模型的性能会显著下降,甚至在简单任务上也变得不可靠。这证明了精巧的上下文工程和精准的检索比简单粗暴地填充上下文窗口更为重要。 RAG 的讣告:被 Agent 杀死,被长上下文掩埋 博客文章:The RAG Obituary: Killed by Agents, Buried by Context Windows 博客地址:https://www.nicolasbustamante.com/p/the-rag-obituary-killed-by-agents 作者指出 RAG 架构从根基上就存在难以克服的「原罪」: 切分的困境:RAG 的第一步「切块」就是灾难的开始。以一份复杂的 SEC 10-K 财报为例,强制按固定长度切分,会将表格的标题与数据分离,风险因素的解释被拦腰斩断,管理层讨论与相关财务数据脱钩。作者所在公司 Fintool 虽开发出保留层级结构、表格完整性、交叉引用等高级切分策略,但这依然是「在碎片上跳舞」,无法解决上下文被物理割裂的根本问题。 检索的噩梦:纯粹的向量搜索在专业领域常常失灵。嵌入模型难以区分「收入确认」(会计政策)和「收入增长」(业务表现)这类术语的细微差别。文章举了一个生动的例子:当查询「公司的诉讼风险」时,RAG 可能只找到明确提及「诉讼」字眼的段落,从而报告 5 亿美元的风险;而实际上,加上或有负债、后续事项、赔偿义务等其他部分,真实风险高达 51 亿美元,相差十倍。 无尽的「补丁」:为了弥补向量搜索的不足,业界引入了混合搜索,结合关键词匹配(如 BM25)与向量语义,并通过 RRF 等算法融合结果。但这还不够,为了提升最终喂给 LLM 内容的质量,还需要增加一个「重排序」环节。每增加一个环节,都意味着延迟的飙升、成本的叠加以及系统复杂性的指数级增长。作者将其形容为「级联失败问题」,任何一环的失误都会被层层放大。 沉重的基础设施负担:维护一个生产级的 Elasticsearch 集群本身就是一项艰巨的任务,涉及 TB 级的索引数据、高昂的内存成本、耗时数天的重建索引以及持续的版本管理和优化。 作者认为,智能体(Agent)和 LLM 长上下文窗口这两项技术进步将直接「杀死」RAG。 作者的「顿悟时刻」来源于 Anthropic 发布的 Claude Code。他发现这个编码助手在没有使用任何 RAG 的情况下,表现远超传统方法。 其秘诀在于放弃了复杂的索引管道,回归了最原始但极其高效的工具:grep(文本搜索)和 glob(文件模式匹配)。 这种「智能体搜索」范式的工作方式是「调查」而非「检索」: 直接访问,而非索引:Agent 可以直接在文件系统上运行 grep,实时、高速地查找信息,无需预处理和索引,也就不存在索引延迟。 完整加载,而非碎片:随着 Claude Sonnet 4 达到 200K、Gemini 2.5 达到 1M、甚至 Grok 4-fast 达到 2M tokens 的上下文窗口,LLM 现在可以直接「读入」整份财报、整个代码库。当你可以阅读全书时,为什么还要满足于几张书签呢? 逻辑导航,而非相似度匹配:Agent 能够像人类分析师一样,在完整文档中进行逻辑跳转。例如,在财报中看到「参见附注 12」,它会直接导航到附注 12,再根据附注内容跳转到其他相关章节,从而构建一个完整的理解链条。 作者的结论并非要彻底消灭 RAG,而是将其「降级」。在新的范式下,RAG 不再是系统的核心架构,而仅仅是 Agent 工具箱中的一个选项。 在面对海量文档需要初步筛选时,Agent 可能会先用混合搜索(RAG 的核心)进行一次粗筛,然后将排名靠前的几份完整文档加载到上下文中,进行深度分析和推理。 结语 然而,RAG 本身所代表的核心思想——为 LLM 提供精准、可靠的外部知识——的需求是永恒的。 未来的图景更可能是: 场景决定架构:对于需要从海量、非结构化数据中快速筛选信息的场景(如智能客服、企业知识库初筛),由 Agent 驱动的、高度工程化的高级 RAG 系统仍是最佳选择。 长上下文的统治力:对于需要对少量、结构复杂的文档进行深度推理和分析的场景(如财报分析、法律合同审查),「长上下文窗口 + Agent 调查」的范式将展现出碾压性的优势。 对于开发者而言,关键在于理解不同技术范式的优劣,并根据具体的应用场景,灵活地将它们组合成最高效、最可靠的解决方案。 更多细节请参看原博客。 该文观点仅代表作者本人,36氪平台仅提供信息存储空间服务。
LlamaIndex Frequently Asked Questions (FAQ)
When was LlamaIndex founded?
LlamaIndex was founded in 2023.
Where is LlamaIndex's headquarters?
LlamaIndex's headquarters is located at 325 5th Street, San Francisco.
What is LlamaIndex's latest funding round?
LlamaIndex's latest funding round is Incubator/Accelerator.
How much did LlamaIndex raise?
LlamaIndex raised a total of $27.5M.
Who are the investors of LlamaIndex?
Investors of LlamaIndex include AWS Generative AI Accelerator, KPMG, Databricks, Greylock Partners, Norwest Venture Partners and 13 more.
Who are LlamaIndex's competitors?
Competitors of LlamaIndex include Lyzr, LangChain, Unstructured, CodeGPT, Aleph Alpha and 7 more.
What products does LlamaIndex offer?
LlamaIndex's products include LlamaCloud and 1 more.
Who are LlamaIndex's customers?
Customers of LlamaIndex include Cemex and Rakuten.
Loading...
Compare LlamaIndex to Competitors

CrewAI develops technology related to multi-agent automation within the artificial intelligence sector. The company provides a platform for building, deploying, and managing AI agents that automate workflows across various industries. Its services include tools, templates for development, and tracking and optimization of AI agent performance. The company was founded in 2024 and is based in Middletown, Delaware.

Cohere operates as an enterprise artificial intelligence (AI) company building foundation models and AI products across various sectors. The company offers a platform that provides multilingual models, retrieval systems, and agents to address business problems while ensuring data security and privacy. Cohere serves financial services, healthcare, manufacturing, energy, and the public sector. It was founded in 2019 and is based in Toronto, Canada.

Contextual AI focuses on retrieval-augmented generation (RAG) in the artificial intelligence (AI) sector. The company provides a platform that allows enterprises to create RAG agents aimed at improving productivity in expert knowledge work. Contextual AI serves companies, offering solutions for subject-matter experts. It was founded in 2023 and is based in Mountain View, California.

Dify operates as a platform for developing generative artificial intelligence (AI) applications within the technology industry. The company provides tools for creating, orchestrating, and managing artificial intelligence (AI) workflows and agents, using large language models (LLMs) for various applications. Dify's services are designed for developers who wish to integrate artificial intelligence (AI) into products through visual design, prompt refinement, and enterprise operations. It was founded in 2023 and is based in San Francisco, California.
CognitivEdge.ai utilizes artificial intelligence (AI) and Generative AI technology within the healthcare industry. Their offerings include early detection of behavioral and mental challenges using data analysis with large language models. The company serves the healthcare sector and works on mental health monitoring and intervention. It was founded in 2023 and is based in Austin, Texas.

MindHYVE.ai is involved in the development of Artificial General Intelligence (AGI), focusing on creating digital employees that operate autonomously across various sectors. The company's main offerings include intelligent agents for healthcare, legal, educational, and financial services, which aim to improve workflows and decision-making. MindHYVE.ai serves industries that require advanced automation and decision-support systems. It was founded in 2022 and is based in Newport Beach, California.
Loading...